m-LoRA
Efficient LLM Model Fine-Tune via Multi-LoRA Optimization
m-LoRA: Efficient LLM Model Fine-Tune via Multi-LoRA Optimization
![]()




m-LoRA (a.k.a Multi-Lora Fine-Tune) is an open-source framework for fine-tuning Large Language Models (LLMs) using the efficient multiple LoRA/QLoRA methods. Key features of m-LoRA include:
-
Efficient LoRA/QLoRA: Optimizes the fine-tuning process, significantly reducing GPU memory usage by leveraging a shared frozen-based model.
-
Multiple LoRA Adapters: Support for concurrent fine-tuning of multiple LoRA/QLoRA adapters.
Overview
m-LoRA is a high-throughput LLM fine-tuning framework based on LoRA and QLoRA, compatible with HuggingFace-Transformers LLaMA Models and ChatGLM Models.
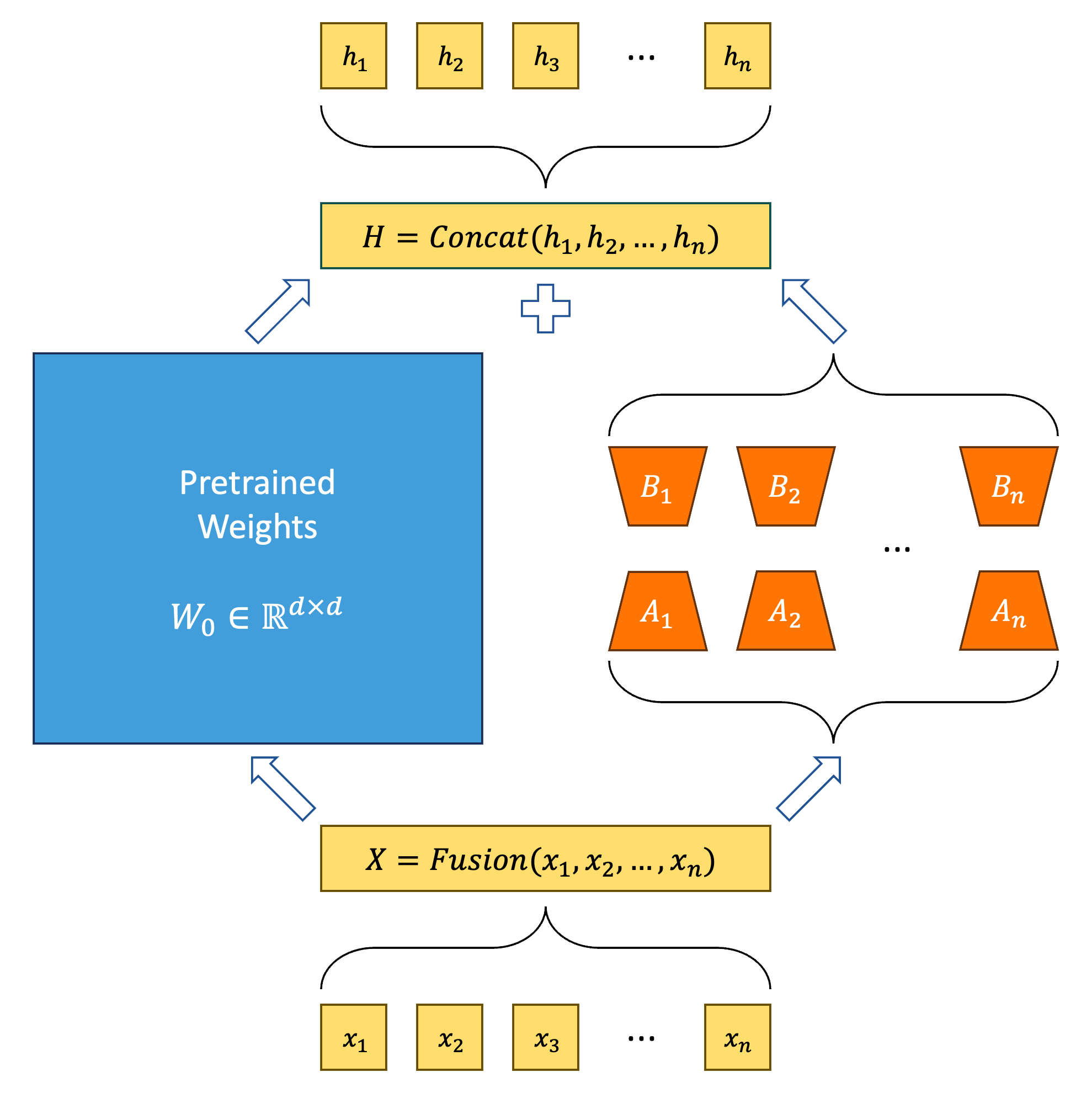
This picture shows the basic principle of LoRA and Multi-LoRA.
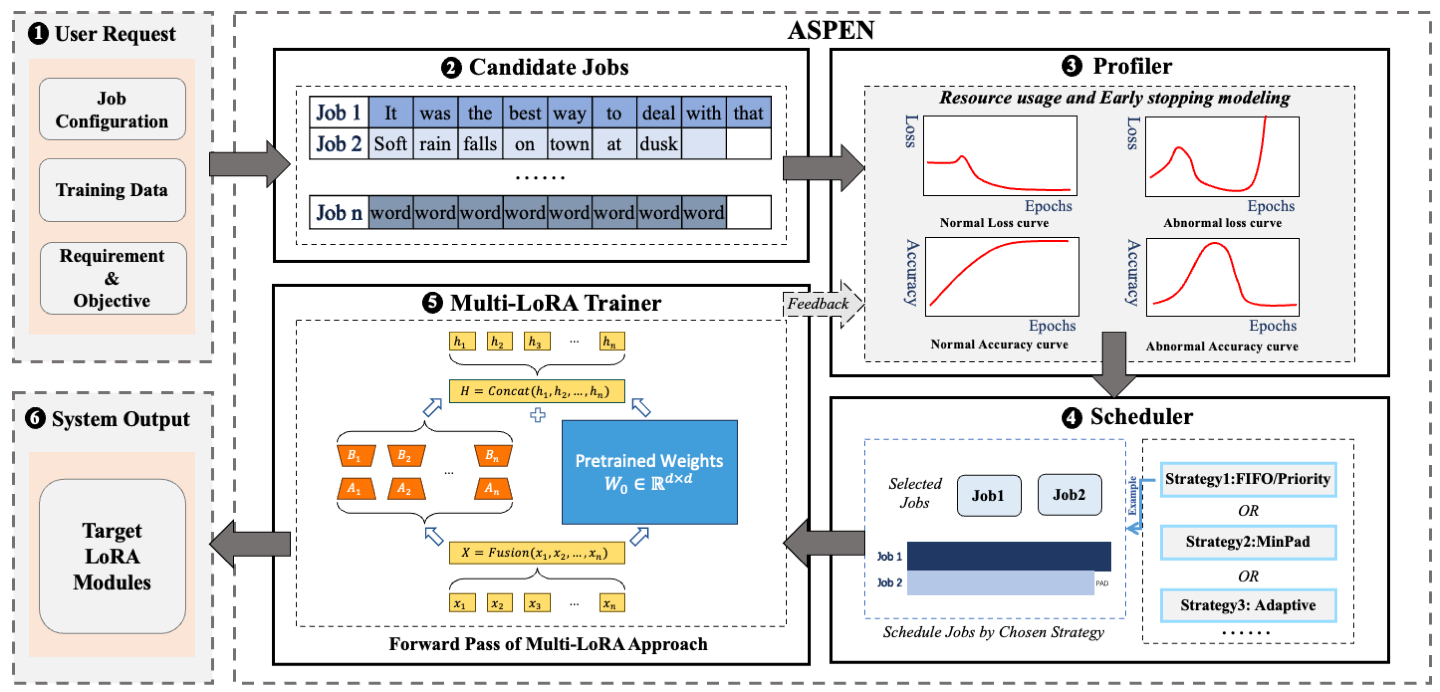
The system overview of m-LoRA is as follows.
m-LoRA requires PyTorch and NVIDIA CUDA compatible GPUs.
Main Contribution
- Introduces the Multi-LoRA method, capable of enabling the sharing of pre-trained model weights during the fine-tuning process of large language models;
- Proposes a task scheduling algorithm to enhance the overall throughput of the task training process and reduce total training latency;
- Builds upon the above by implementing m-LoRA, a high-throughput large language model fine-tuning framework based on LoRA and QLoRA;
- Evaluates m-LoRA in experiments against existing systems, confirming that m-LoRA effectively utilizes system computing resources, thereby improving training throughput and reducing training latency compared to current systems.
Experiment Results
Environment: NVIDIA RTX A6000 with Intel Xeon Silver 4314 on Ubuntu 22.04.3
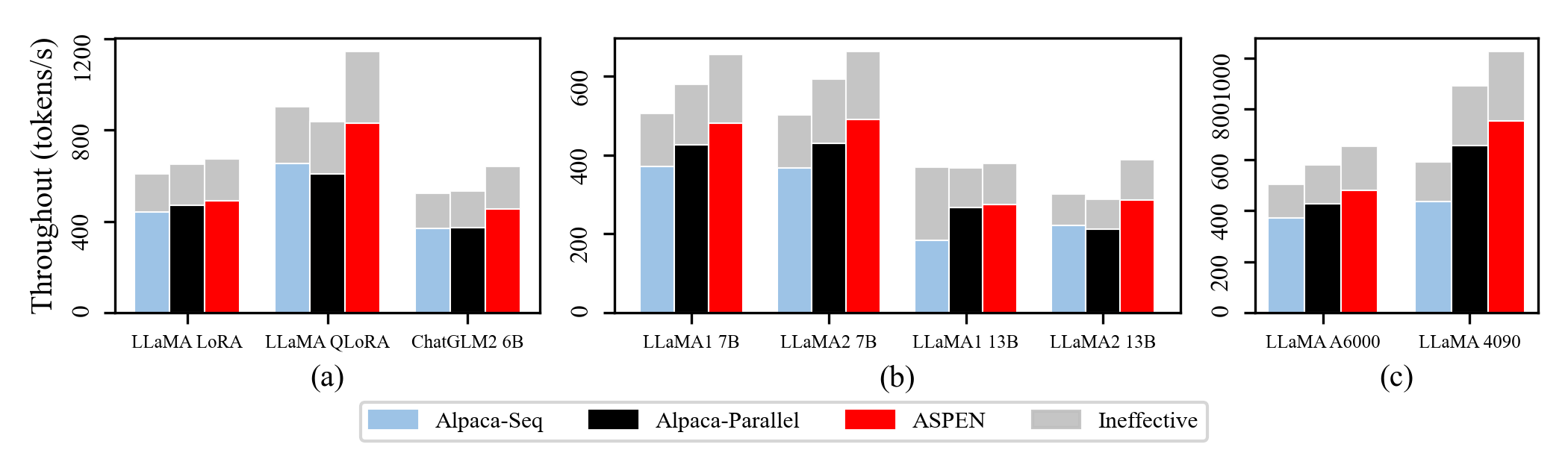
Baseline: We utilized the widely adopted Alpaca-LoRA as a foundation. On a single GPU, we independently ran multiple Alpaca-LoRA processes in parallel (marked as Baseline@Alpaca-Parallel) and sequentially (marked as Baseline@Alpaca-Seq), forming two baseline methods for the experiments. We test this on A100, and rest of results are based on the same GPU configure.
Training Latency and Throughput
| Method | Latency | Throughput |
|---|---|---|
| Baseline@Alpaca-Seq | 10.51h | 608.41 token/s |
| Baseline@Alpaca-Parallel | 9.85h | 649.30 token/s |
| m-LoRA | 9.46h | 674.58 token/s |
We conducted four identical fine-tuning jobs with same dataset and same hyper-parameters, incorporating two baselines and m-LoRA. During the experimental process, we collected the completion times for each task in the baseline methods and calculated the time taken by the slowest task as the Training Latency. As shown in Table, m-LoRA exhibits lower Training Latency compared to both baseline methods. Specifically, m-LoRA is 9.99% faster than Baseline@Alpaca-Seq and 3.92% faster than Baseline@Alpaca-Parallel.
Video Memory Usage
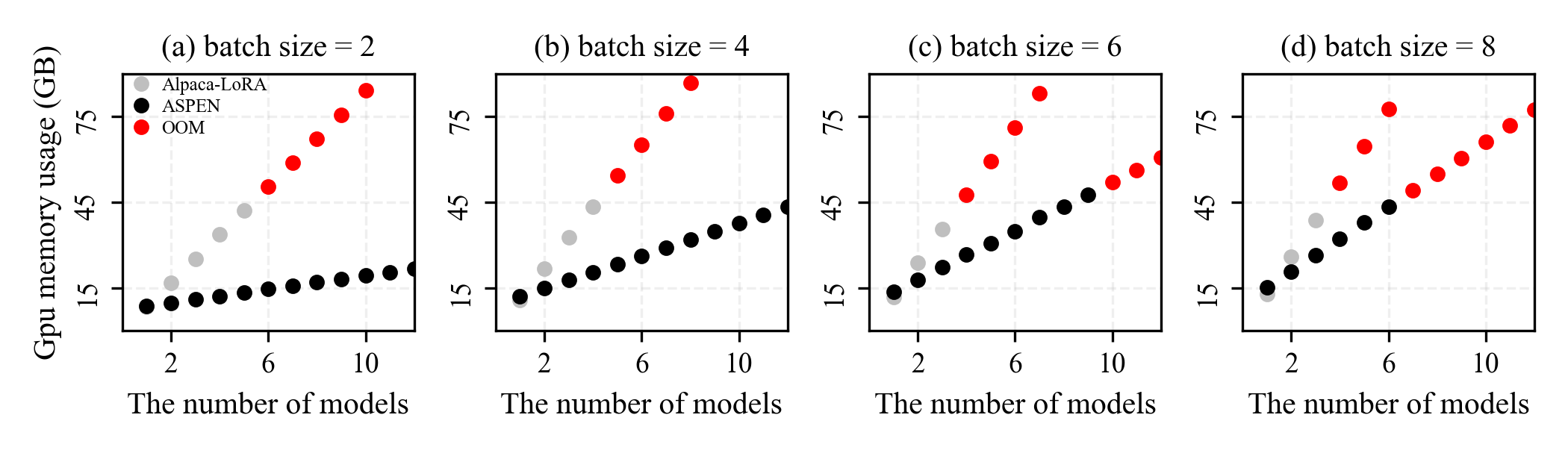
We conducted several fine-tuning jobs with same dataset and batch_size = {2,4, 6, 8}, incorporating Baseline@Alpaca-Parallel and m-LoRA.
Baseline@Alpaca-Parallel triggered OOM error after 3 parallel tasks when batch size = 8, while m-LoRA can handle twice that amount.
Batching Strategies
| Method | Training Latency | Peak Memory Usage | Average GPU Utilization | Training Throughput |
|---|---|---|---|---|
| Baseline@Alpaca-Seq | 27.73h | 10.68GB | 79.39% | 653.35 token/s |
| m-LoRA@M1 | 36.82h | 23.82GB | 96.52% | 672.54 token/s |
| m-LoRA@M2 | 39.14h | 23.86GB | 96.41% | 671.28 token/s |
| m-LoRA@M3 | 22.97h | 23.85GB | 95.22% | 674.41 token/s |
We conducted four fine-tuning jobs with different dataset but same hyper-parameters, incorporating Baseline@Alpaca-Seq and m-LoRA.
During the experimental process, we collected following metrics:
- Training Latency = Job completion time
- Throughput = The number of passed tokens in model forward process / training latency
- Memory Usage = Peak video memory usage
- GPU Utilization = Average GPU utilization
All metrics are computed for each job. M1, M2, M3 represent three batch strategies of m-LoRA: Optimal-Fit, Trivial, and Fast-Fit. BASELINE denotes Baseline@Alpaca-Seq.
The Optimal-Fit strategy performs the best across all four metrics, while the other two strategies also outperform the baseline method other than training latency.
Use Cases:
- Domain-Specific Fine-Tuning: This involves adapting a single model with various parameters particularly for one domain.
- Cross-Domain Fine-Tuning: This method leverages the base model to fine-tune multiple models, each intended for a different domain.